
I vantaggi del progresso tecnologico sono apparentemente infiniti. Possiamo controllare la sicurezza delle nostre case dai nostri telefoni, ricevere consegne di generi alimentari da parte di droni e persino guidare auto che possono parcheggiare in parallelo per noi. I nostri televisori stanno diventando altrettanto avanzati, offrendo una scelta di contenuti apparentemente infinita attraverso un panorama di piattaforme e canali in continua crescita. Tuttavia, nonostante le numerose porte che le smart TV apriranno nei prossimi anni, non saranno in grado da sole di fornire al settore dei media una visione accurata di chi le utilizza.
I televisori intelligenti hanno conquistato la corsia dei televisori della grande distribuzione locale. Oggi è difficile trovare in un negozio un televisore che non sia connesso a Internet. E come tutti i dispositivi connessi, le smart TV contribuiscono alla crescente proliferazione di dati generati dagli utenti: I dati del riconoscimento automatico dei contenuti (ACR) sono la tecnologia che gli OEM utilizzano per acquisire la sintonizzazione sulle smart TV. Se combinati con informazioni che dettagliano il comportamento rappresentativo a livello personale, questi set di dati fanno progredire in modo significativo la scienza della misurazione dell'audience.
Data l'ampia adozione delle smart TV e dei dati che producono, non sorprende che una serie di aziende stia guardando ai dati ACR come metodo per misurare l'audience. Dal punto di vista della scala, l'opportunità è molto interessante. Tuttavia, per quanto l'ACR sia una fonte di dati redditizia, non è sufficiente da sola a misurare l'audience, semplicemente perché manca l'aspetto più importante nella misurazione dell'audience: le persone. Oltre a non essere rappresentativi - oaddirittura a nonsapere se qualcuno sta effettivamente guardando ciò che è sullo schermo - i dati ACR hanno un difetto critico di validazione: richiedono che il produttore del dispositivo abbini l'immagine sullo schermo a un'immagine di riferimento per determinare quale contenuto viene visualizzato. Pertanto, il modo migliore per sbloccare il vero potenziale dei dati ACR è quello di calibrarli con dati che riflettano il vero comportamento di visione a livello personale.
Quando funziona come previsto, la tecnologia ACR monitora le immagini proiettate sul vetro del televisore e le utilizza per dedurre il contenuto visualizzato. Le immagini servite dall'ACR agiscono per molti versi come un'impronta digitale del contenuto. Ma dopo aver raccolto le "impronte digitali", la tecnologia deve determinare su quale rete o piattaforma è apparsa l'immagine e quando è apparsa. Per fare questa determinazione, la tecnologia deve confrontare l'immagine sullo schermo con un'immagine contenuta in una libreria di riferimento gestita dal produttore.
Ci sono tre possibili risultati quando la tecnologia tenta di fare questa corrispondenza:
- L'immagine corrisponde a una singola voce della libreria di riferimento
- L'immagine corrisponde a più voci della libreria di riferimento
- Un'immagine corrispondente non è presente nella libreria di riferimento
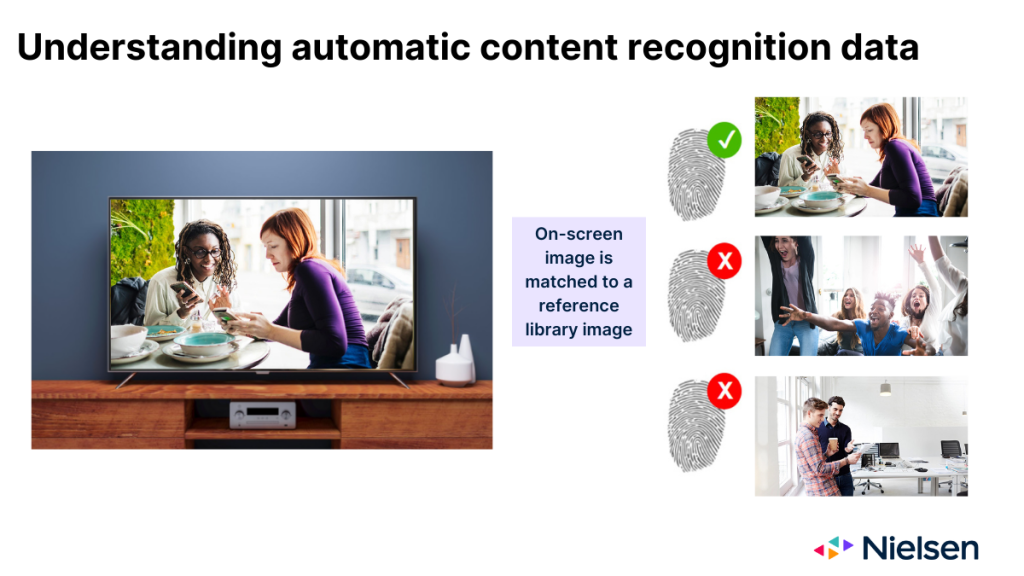
Per tutte le parti coinvolte, il primo risultato è lo scenario ideale. Il secondo scenario è meno ideale e comporta un certo livello di rischio di errore di accreditamento, semplicemente a causa delle varie ragioni per cui si verificano le partite multiple (ad esempio, trasmissioni su più reti, ripetizioni, simulcast). Nel terzo scenario, nessuno ottiene il credito, che è ovviamente lo scenario meno auspicabile. La ragione più comune di questo risultato è che il contenuto è andato in onda su una rete che l'OEM non controlla.
Anche se la corrispondenza delle immagini fosse una soluzione di misurazione autonoma, la capacità di sfruttarla come tale non sarebbe mai realizzabile. Come si può immaginare, il costo per mantenere una libreria di ogni singolo fotogramma di ogni evento televisivo non è un compito da poco. Ed è anche un compito che crescerà in modo esponenziale in perpetuo. Inoltre, non esistono periodi di conservazione standard per le immagini.
Come facciamo a sapere che la tecnologia ACR farà l'abbinamento giusto? Senza un meccanismo in grado di riempire gli spazi vuoti, non lo sappiamo. Ecco perché Nielsen ha investito nei watermark, che sono molto più deterministici delle firme, e nei backup delle firme per ogni feed misurato. In questo modo si ottiene una rappresentazione di tutti i contenuti, colmando le lacune associate ai big data di per sé. Una volta colmate queste lacune, i big data provenienti da fonti come ACR offrono il vantaggio della scala in un panorama mediatico sempre più segmentato. E quando utilizziamo i controlli di ponderazione per calibrare i big data con i dati di visualizzazione a livello di persona, siamo in grado di vedere punti di confronto che altrimenti sarebbero vuoti.
In uno studio recente, Nielsen ha cercato di capire in che misura queste lacune della libreria di riferimento influenzino i log di sintonizzazione ACR, la base per la misurazione basata su ACR. In un'analisi delle case comuni del settembre 2021, abbiamo analizzato i dati dei nostri due partner fornitori di ACR per capire dove le lacune delle librerie di riferimento possano influire sulla misurazione. Nel nostro studio abbiamo esaminato sia la concentrazione di fonti di visione che i minuti di visione delle fonti disponibili.
Tra tutte le fonti di visualizzazione, abbiamo scoperto che i nostri partner fornitori di ACR monitorano solo il 31% delle stazioni disponibili. Ciò significa che non mantengono i dati nelle loro biblioteche di riferimento per il 69% delle stazioni. Quando abbiamo esaminato i minuti visualizzati, abbiamo scoperto che il 23% dei minuti proveniva da stazioni non monitorate. Ciò significa che le aziende che si basano solo sui dati ACR per la misurazione, sottovalutano le impressioni a livello domestico del 23%.
Nonostante i limiti dei dati ACR da soli, comprendiamo l'opportunità di scala e di portata che essi offrono come fonte aggiuntiva di copertura, simile a quella dei dati sul percorso di ritorno (RPD) dai set-top box, che la nostra strategia di big data calibra anche con i dati dei panel per affrontare limitazioni comparabili. Integrando i set di big data con i nostri dati di ascolto, che forniscono una misurazione rappresentativa del totale degli Stati Uniti, siamo in grado di aumentare in modo significativo le dimensioni dei nostri campioni, applicando al contempo rigorose metodologie di data science per colmare le lacune e garantire un'equa rappresentazione dell'audience totale degli Stati Uniti attraverso tutte le reti e le piattaforme.
Una versione di questo articolo è apparsa originariamente su AdExchanger.



