
テクノロジーの進歩がもたらす恩恵は無限ともいえる。携帯電話で自宅のセキュリティをチェックしたり、ドローンで食料品の配達を受けたり、さらには縦列駐車が可能な車を運転したり。テレビも同様に進化しており、増え続けるプラットフォームやチャンネルから、無限のコンテンツが選べるようになっている。しかし、スマートTVが今後数年のうちに開くであろう多くの扉にもかかわらず、それ自体では、メディア業界は、誰がスマートTVを使っているのかを正確に把握することはできないだろう。
スマートテレビは、近所の大型小売店のテレビ売り場を席巻している。今日、店頭でインターネットに対応していないテレビを見つけるのは難しいだろう。そして、他のコネクテッド・デバイスと同様に、スマート・テレビは、ユーザー生成データの急増に拍車をかけている:自動コンテンツ認識(ACR)データは、OEMがスマートテレビのチューニングをキャプチャするために使用する技術である。自動コンテンツ認識(ACR)データは、OEMがスマートTVのチューニングをキャプチャするために使用する技術である。代表的な個人レベルの行動を詳細に示す情報と組み合わせることで、これらのデータセットは視聴者測定の科学を大きく前進させる。
スマートTVの普及とそこから得られるデータを考えれば、多くの企業が視聴者を測定する方法としてACRデータに注目しているのは驚くことではない。規模の観点からすれば、このチャンスは非常に魅力的だ。しかし、ACRが有益なデータソースであるとしても、それだけで視聴者を測定するには不十分である。ACRデータには 、代表的なものではないことに加え 、誰かが実際に画面上のものを見ているかどうかさえ分からないという致命的な検証上の欠陥がある。したがって、ACRデータの真の可能性を引き出す最善の方法は、真の人レベルの視聴行動を反映するデータで校正することである。
ACRテクノロジーは、設計通りに動作する場合、テレビガラスに投影される画像をモニターし、その画像から表示されるコンテンツを推測する。ACRが提供する画像は、多くの点でコンテンツの指紋のように機能する。しかし、"フィンガープリント "を収集した後、このテクノロジーは、画像がどのネットワークやプラットフォームに表示されたのか、またいつ表示されたのかを判断する必要がある。この判断を下すために、テクノロジーは画面上の画像を、メーカーが管理する参照ライブラリに含まれる画像と照合する必要がある。
テクノロジーがそのマッチングを試みた場合、3つの結果が考えられる:
- 画像はリファレンス・ライブラリーの1つのエントリーと一致する
- 画像はリファレンスライブラリの複数のエントリと一致します。
- 一致する画像がレファレンス・ライブラリにない
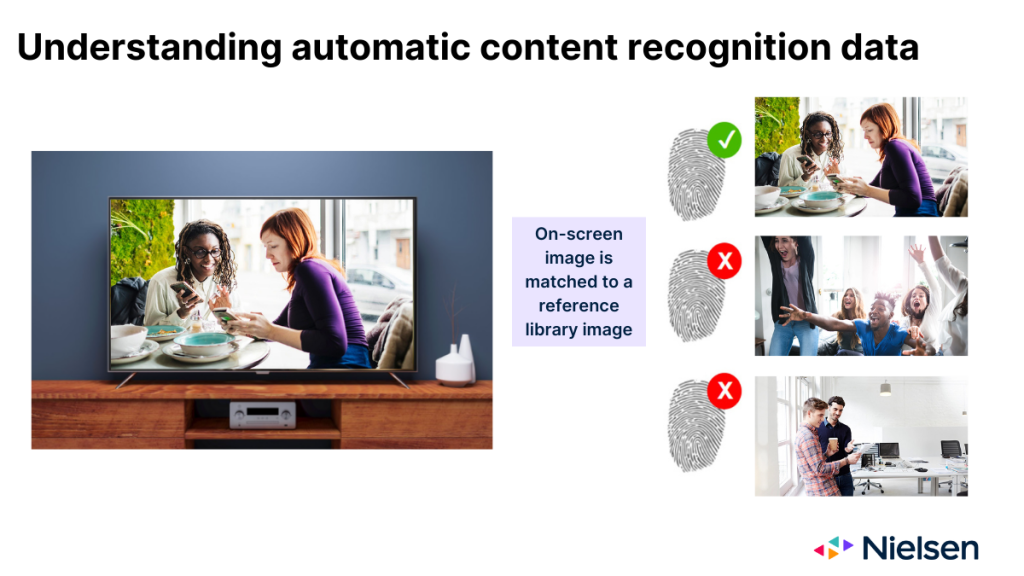
すべての関係者にとって、最初の結果は理想的なシナリオである。2つ目のシナリオは理想的とは言えず、単純に複数の試合が行われるさまざまな理由(ネットワークをまたいだ放映、リピート放映、サイマル放送など)から、ある程度のミスクレジットのリスクが伴う。3つ目のシナリオでは、誰もクレジットを得られないが、これは明らかに最も望ましくないシナリオである。このような結果になる最も一般的な理由は、OEMが監視していないネットワークでコンテンツが放映されたからである。
画像マッチングが単独で実行可能な測定ソリューションであったとしても、それを活用する能力は決して実現可能なものではないだろう。ご想像の通り、テレビで放映されるあらゆるイベントのあらゆるフレームのライブラリを維持するコストは、決して小さな仕事ではない。それはまた、永続的に指数関数的に増大する作業でもある。また、画像の標準的な保存期間もない。
では、ACRの技術が正しいマッチングをすることを、私たちはどうやって知ることができるのだろうか?空白を埋めるメカニズムがなければ、わからない。そのためニールセンは、署名よりもはるかに決定論的な透かしや、すべての測定フィードの署名のバックアップに投資してきた。これにより、すべてのコンテンツの表現が可能になり、ビッグデータに関連するギャップを埋めることができる。これらのギャップを埋めることで、ACRのようなソースから得られるビッグデータは、ますます細分化されるメディアの状況において、スケールのメリットを提供する。また、重み付けコントロールを使ってビッグデータを個人レベルの視聴データで校正すると、そうでなければ空白になっていた比較ポイントが見えるようになる。
ニールセンは最近の調査で、こうしたレファレンス・ライブラリーのギャップが、ACRベースの測定の基礎であるACRチューニング・ログにどの程度影響するかを調査した。2021年9月のコモンホームの分析では、2つのACRプロバイダー・パートナーのデータを分析し、リファレンス・ライブラリのギャップが測定にどのように影響するかを理解した。この調査では、視聴ソースの集中度と、利用可能なソースからの視聴分数の両方を調べました。
すべての視聴ソースにおいて、ACRプロバイダー・パートナーは利用可能な放送局の31%しかモニターしていないことがわかった。つまり、69%の放送局について、レファレンス・ライブラリーにデータを保持していないことになる。視聴された分数を見てみると、分数の23%はモニターされていない放送局からのものであった。つまり、ACRデータだけで測定している企業は、世帯レベルのインプレッションを23%も過小評価していることになる。
ACRデータ単体では限界がありますが、セットトップボックスからのリターンパス・データ(RPD)と同様に、追加的なカバレッジ・ソースとしてACRデータが提供するスケールとリーチの機会を理解しています。ビッグデータセットと、全米を代表する視聴データを統合することで、サンプル数を大幅に増やすことができる一方、厳格なデータサイエンスの手法を適用してギャップを埋め、すべてのネットワークとプラットフォームにわたって全米の視聴者を公平に表現することができます。
この記事はAdExchangerに掲載されたものです。



