
Korzyści płynące z rozwoju technologii są pozornie nieograniczone. Możemy sprawdzać bezpieczeństwo naszych domów z naszych telefonów, odbierać dostawy spożywcze za pomocą dronów - a nawet prowadzić samochody, które mogą parkować równolegle za nas. Nasze telewizory stają się równie zaawansowane, oferując pozornie nieskończony wybór treści na stale rosnącym krajobrazie platform i kanałów. Jednak pomimo wielu drzwi, które inteligentne telewizory otworzą w nadchodzących latach, same w sobie nie będą w stanie zapewnić branży medialnej dokładnego obrazu tego, kto z nich korzysta.
Telewizory Smart TV opanowały alejkę z telewizorami w lokalnych sklepach wielkopowierzchniowych. Trudno dziś znaleźć w sklepie telewizor, który nie jest podłączony do Internetu. Podobnie jak wszystkie podłączone urządzenia, inteligentne telewizory przyczyniają się do rosnącej liczby danych generowanych przez użytkowników: Dane automatycznego rozpoznawania treści (ACR) to technologia wykorzystywana przez producentów OEM do przechwytywania ustawień telewizorów Smart TV. W połączeniu z informacjami, które wyszczególniają reprezentatywne zachowania na poziomie osoby, te zestawy danych znacznie rozwijają naukę o pomiarach oglądalności.
Biorąc pod uwagę szerokie zastosowanie inteligentnych telewizorów i generowanych przez nie danych, nie jest zaskakujące, że szereg firm poszukuje danych ACR jako sposobu pomiaru odbiorców. Z perspektywy samej skali, możliwość ta jest bardzo atrakcyjna. Jednak tak lukratywne źródło danych, jakim jest ACR, samo w sobie nie wystarcza do pomiaru oglądalności, po prostu dlatego, że brakuje mu najważniejszego aspektu pomiaru oglądalności: ludzi. Oprócz tego, że dane ACR nie są reprezentatywne - aninawet świadome, czy ktoś faktycznie ogląda to, co jest na ekranie - mają krytyczną wadę walidacyjną: wymagają od producenta urządzenia dopasowania obrazu na ekranie do obrazu referencyjnego w celu ustalenia, jaka treść jest wyświetlana. Tak więc najlepszym sposobem na uwolnienie prawdziwego potencjału danych ACR jest skalibrowanie ich za pomocą danych, które odzwierciedlają rzeczywiste zachowanie osoby podczas oglądania.
Gdy działa zgodnie z przeznaczeniem, technologia ACR monitoruje obrazy wyświetlane na szybie telewizora i wykorzystuje je do wnioskowania, jaka treść jest wyświetlana. Obrazy obsługiwane przez ACR działają pod wieloma względami jak odciski palców treści. Ale po zebraniu "odcisków palców" technologia musi określić, w której sieci lub na jakiej platformie pojawił się obraz, a także kiedy się pojawił. Aby to ustalić, technologia musi dopasować obraz na ekranie do obrazu zawartego w bibliotece referencyjnej utrzymywanej przez producenta.
Istnieją trzy możliwe wyniki, gdy technologia próbuje dokonać takiego dopasowania:
- Obraz pasuje do pojedynczego wpisu w bibliotece referencyjnej
- Obraz pasuje do wielu wpisów w bibliotece referencyjnej
- Pasującego obrazu nie ma w bibliotece referencyjnej
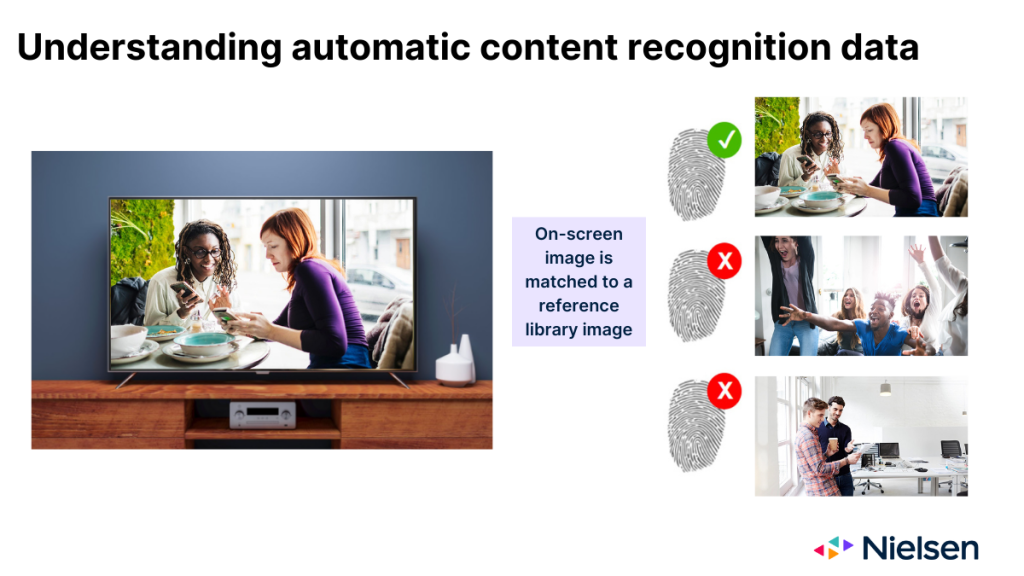
Dla wszystkich zaangażowanych stron pierwszy wynik jest idealnym scenariuszem. Drugi scenariusz jest mniej idealny i wiąże się z pewnym poziomem ryzyka błędnego zaliczenia, po prostu z powodu różnych powodów wielu meczów (np. emisji w różnych sieciach, powtórek, simulcastów). W trzecim scenariuszu nikt nie otrzymuje punktów, co jest oczywiście najmniej pożądanym scenariuszem. Najczęstszym powodem takiego wyniku jest fakt, że treści były emitowane w sieci, której OEM nie monitoruje.
Nawet gdyby dopasowywanie obrazu było realnym, samodzielnym rozwiązaniem pomiarowym, możliwość wykorzystania go jako takiego nigdy nie byłaby wykonalna. Jak można sobie wyobrazić, koszt utrzymania biblioteki każdej pojedynczej klatki każdego wydarzenia w telewizji to niemałe zadanie. Jest to również zadanie, które będzie rosło wykładniczo w nieskończoność. Nie ma również standardowych okresów przechowywania obrazów.
Skąd więc mamy wiedzieć, że technologia ACR zapewni właściwe dopasowanie? Bez mechanizmu, który może wypełnić puste pola, nie wiemy. Dlatego Nielsen zainwestował w znaki wodne, które są znacznie bardziej deterministyczne niż podpisy, a także w kopie zapasowe podpisów dla każdego mierzonego kanału. Zapewnia to reprezentację całej zawartości - wypełniając luki związane z samymi dużymi danymi. Po wypełnieniu tych luk, duże zbiory danych pochodzące ze źródeł takich jak ACR zapewniają korzyści skali w coraz bardziej podzielonym krajobrazie medialnym. A kiedy używamy kontroli wagi do kalibracji dużych danych z danymi oglądalności na poziomie osoby, jesteśmy w stanie zobaczyć punkty porównawcze, które w przeciwnym razie byłyby puste.
W niedawnym badaniu Nielsen starał się zrozumieć, w jakim stopniu te luki w bibliotekach referencyjnych wpływają na dzienniki strojenia ACR - podstawę pomiaru opartego na ACR. W analizie Common Homes z września 2021 r. przeanalizowaliśmy dane od naszych dwóch partnerów dostarczających ACR, aby zrozumieć, gdzie luki w bibliotekach referencyjnych mogą mieć wpływ na pomiary. W naszym badaniu przyjrzeliśmy się zarówno koncentracji źródeł oglądania, jak i obejrzanym minutom z dostępnych źródeł.
We wszystkich źródłach oglądania stwierdziliśmy, że nasi partnerzy ACR monitorują tylko 31% dostępnych stacji. Oznacza to, że nie przechowują oni danych w swoich bibliotekach referencyjnych dla 69% stacji. Kiedy przyjrzeliśmy się oglądanym minutom, stwierdziliśmy, że 23% minut pochodziło ze stacji, które nie są monitorowane. Oznacza to, że firmy wykorzystujące do pomiaru wyłącznie dane ACR zaniżałyby liczbę wyświetleń na poziomie gospodarstwa domowego o 23%.
Pomimo ograniczeń samych danych ACR, zdajemy sobie sprawę z możliwości skali i zasięgu, jakie zapewniają one jako dodatkowe źródło pokrycia - podobnie jak w przypadku danych o ścieżce powrotnej (RPD) z dekoderów, które nasza strategia big data również kalibruje z danymi panelowymi, aby zaradzić porównywalnym ograniczeniom. Integrując zestawy dużych zbiorów danych z naszymi danymi dotyczącymi oglądalności, które zapewniają reprezentatywny pomiar całej populacji USA, jesteśmy w stanie znacznie zwiększyć nasze próby, jednocześnie stosując rygorystyczne metodologie nauki o danych, aby wypełnić luki i zapewnić uczciwą reprezentację całkowitej widowni w USA we wszystkich sieciach i platformach.
Wersja tego artykułu pierwotnie ukazała się na AdExchanger.



